|
“””
title: “Suicide 2003-2013”
author: “Gilberto Diaz | Jacob Jones | Ashwini Yenamandra | Toni Brandt”
date: “July 2, 2016”
output: html_document
—
—-
# Data & Environment Preparation
“`{r setup, include=FALSE}
knitr::opts_chunk$set(echo = TRUE)
“`
### Set working environment
“`{r setwd}
setwd(‘~/Documents/r_projects/practicum_1/cdc_mortality_2003_2012/suicide_2013_2003/’)
“`
### Loading libraries
“`{r libraries, message = FALSE}
library(dplyr)
library(ggplot2)
library(gridExtra)
library(rmarkdown)
“`
### Loading suicide data sets by year (2003-2013).
“`{r, warning = FALSE, message = FALSE}
suicide.2003 <- read.csv(file = ‘suicide.final.2003.csv’,
header = TRUE,
stringsAsFactors = FALSE)
suicide.2003 <- tbl_df(suicide.2003)
suicide.2004 <- read.csv(file = ‘suicide.final.2004.csv’,
header = TRUE,
stringsAsFactors = FALSE)
suicide.2004 <- tbl_df(suicide.2004)
suicide.2005 <- read.csv(file = ‘suicide.final.2005.csv’,
header = TRUE,
stringsAsFactors = FALSE)
suicide.2005 <- tbl_df(suicide.2005)
suicide.2006 <- read.csv(file = ‘suicide.final.2006.csv’,
header = TRUE,
stringsAsFactors = FALSE)
suicide.2006 <- tbl_df(suicide.2006)
suicide.2007 <- read.csv(file = ‘suicide.final.2007.csv’,
header = TRUE,
stringsAsFactors = FALSE)
suicide.2007 <- tbl_df(suicide.2007)
suicide.2008 <- read.csv(file = ‘suicide.final.2008.csv’,
header = TRUE,
stringsAsFactors = FALSE)
suicide.2008 <- tbl_df(suicide.2008)
suicide.2009 <- read.csv(file = ‘suicide.final.2009.csv’,
header = TRUE,
stringsAsFactors = FALSE)
suicide.2009 <- tbl_df(suicide.2009)
suicide.2010 <- read.csv(file = ‘suicide.final.2010.csv’,
header = TRUE,
stringsAsFactors = FALSE)
suicide.2010 <- tbl_df(suicide.2010)
suicide.2011 <- read.csv(file = ‘suicide.final.2011.csv’,
header = TRUE,
stringsAsFactors = FALSE)
suicide.2011 <- tbl_df(suicide.2011)
suicide.2012 <- read.csv(file = ‘suicide.final.2012.csv’,
header = TRUE,
stringsAsFactors = FALSE)
suicide.2012 <- tbl_df(suicide.2012)
suicide.2013 <- read.csv(file = ‘suicide.final.2013.csv’,
header = TRUE,
stringsAsFactors = FALSE)
suicide.2013 <- tbl_df(suicide.2013)
“`
### Binding all suicide data sets into one dataframe.
“`{r, warning = FALSE, message = FALSE}
suicide.11.years <- rbind(suicide.2003, suicide.2004, suicide.2005, suicide.2006,
suicide.2007, suicide.2008, suicide.2009, suicide.2010,
suicide.2011, suicide.2012, suicide.2013)
“`
### Summary statistic
“`{r , message = FALSE}
ss11y <- summary(suicide.11.years)
ss11y
“`
“`{r , message = FALSE}
age.outlier = suicide.11.years %>%
filter(Age_Value == 999)
count(age.outlier)
count(age.outlier) / count(suicide.11.years) * 100
“`
|Variable|Description|
|:——-|:———-|
|Education|NA’s: 233733 / no education level|
|Age_Value|Max: 999 / 121 outliers; 0.03%|
|Age_Value|Mean: 46.8 / age most people suicide|
|Race_Bridged|NA’s: 398143|
|Race_Imputation|NA’s: 397188|
### Count observations by year
“`{r , message = FALSE}
suicide.by.year<- suicide.11.years %>%
group_by(Data_Year) %>%
select(Data_Year) %>%
summarise(Freq = n())
suicide.by.year
“`
### Graphing suicide frequency by year.
“`{r, warning = FALSE, message = FALSE}
ggplot(suicide.11.years, aes(x = Data_Year, fill = factor(Data_Year))) +
geom_histogram(bins = 11, binwidth = 0.5) +
scale_x_continuous(breaks = seq(2003, 2013, 1)) +
coord_flip() +
labs(x = ‘Year’,
y = ‘Frequency’,
title = ‘Suicide Frequency by Year’,
fill = ‘Year’) +
theme(plot.title = element_text(family = ‘Helvetica’,
color = ‘#666666’,
face = ‘bold’,
size = 18)) +
theme(axis.title = element_text(family = ‘Helvetica’,
color = ‘#666666’,
face = ‘bold’,
size = 12)) +
theme(axis.title.y = element_text(angle = 360))
“`
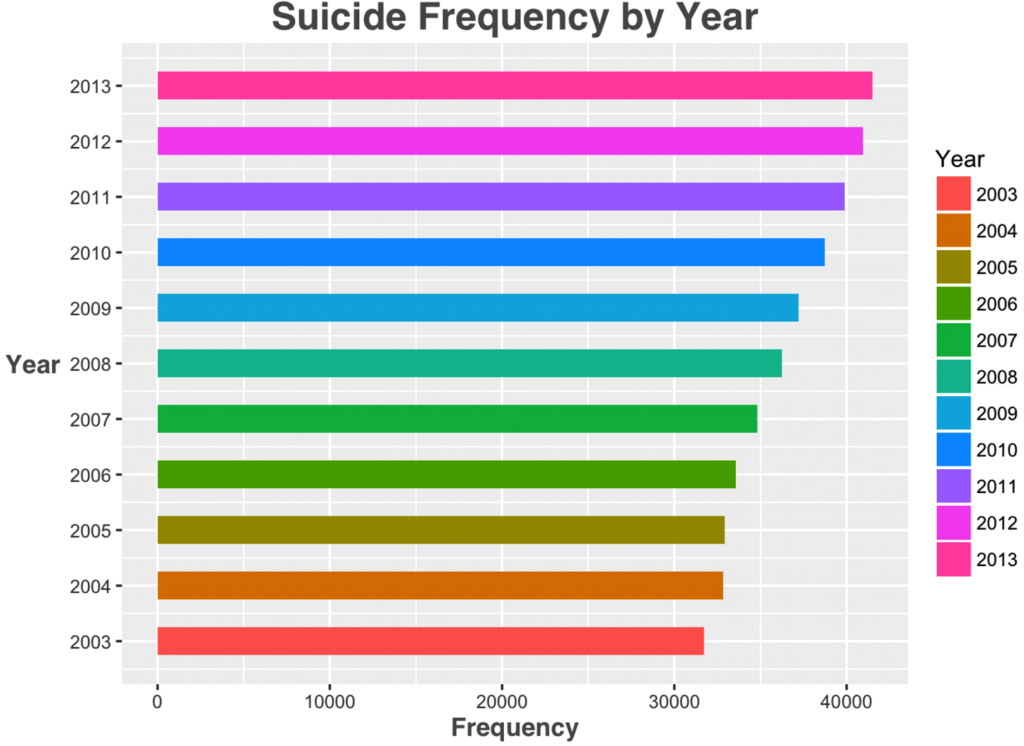
Please notice that suicide frequency has a non stop increase for 11 years.
### Analyzing by education level.
“`{r , message = FALSE}
edu.table<- table(Education = suicide.11.years$Education, useNA = ‘always’)
edu.table
edu.table<- as.data.frame(edu.table)
edu.na.percentage<- edu.table %>%
summarise(Percentage_With_Education_Level = sum(edu.table[1:18, ‘Freq’]) / sum(edu.table[, ‘Freq’]) * 100)
edu.na.percentage
“`
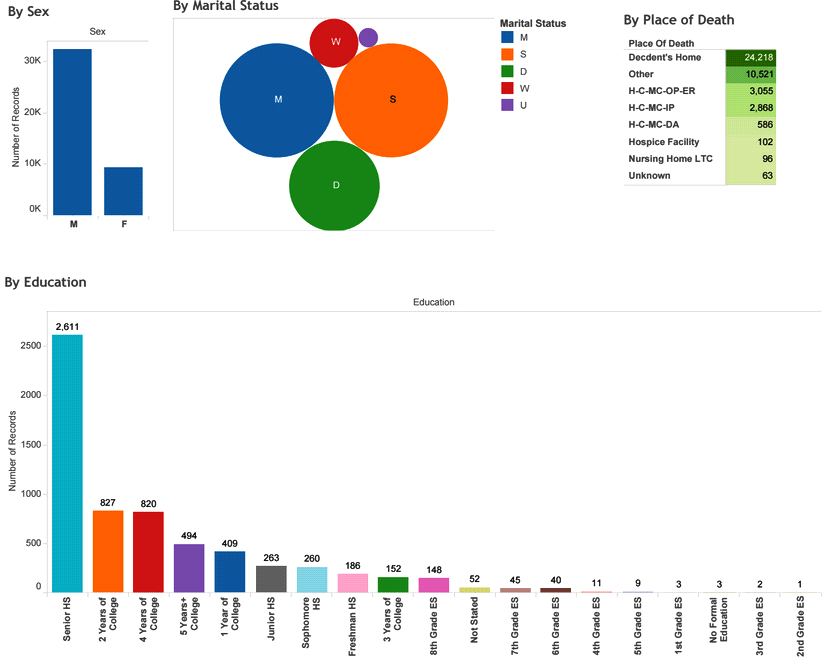
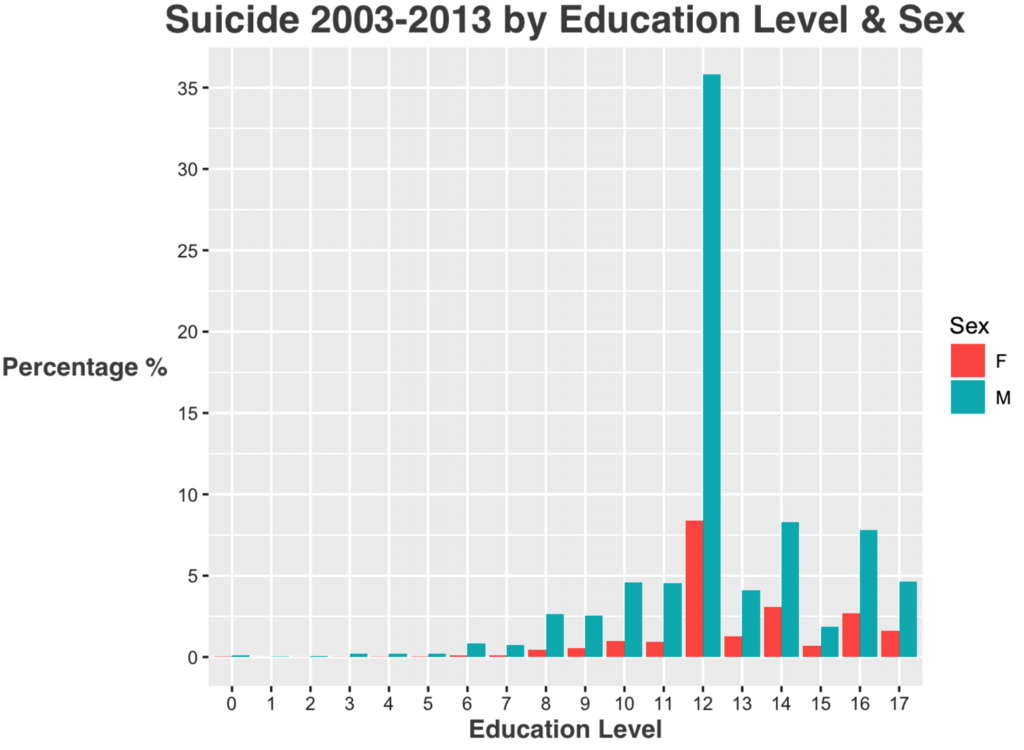
Suicide for all 11 years has **400349** observations. After grouping by education level is found that **241379** observations don’t have education level reported or NA’s (empty). Therefore, the amount of **observations that do have education level is almost 40%**.
### Suicide 2003-2013 percentage group by education and sex. Observations with no education level are excluded.
“`{r, warning = FALSE, message = FALSE}
percentage.by.education.sex<- suicide.11.years %>%
filter(Age_Value<= 250, Education != ‘NA’, Education != 99) %>%
select(Resident_Status, Education, Sex) %>%
group_by(Education, Sex) %>%
summarise(Percentage = n() / length(.$Resident_Status) * 100)
percentage.by.education.sex
“`
### Percentage of people with more than a bachelor degree
“`{r, massage = FALSE}
more.bachelor<- percentage.by.education.sex %>%
filter(between(Education, 13, 17))
sum(more.bachelor$Percentage)
“`
### Graphing suicide 2003-2013 group by education & sex
“`{r, warning = FALSE, message = FALSE}
ggplot(percentage.by.education.sex, aes(x = factor(Education), y = Percentage, fill = Sex)) +
geom_bar(stat = “identity”, position = position_dodge()) +
scale_x_discrete(name = “Education Level”) +
scale_y_continuous(name = “Percentage %”,
breaks = seq(0, 40, by = 5)) +
labs(title = “Suicide 2003-2013 by Education Level & Sex”) +
theme(plot.title = element_text(family = ‘Helvetica’,
color = ‘#666666’,
face = ‘bold’,
size = 18)) +
theme(axis.title = element_text(family = ‘Helvetica’,
color = ‘#666666’,
face = ‘bold’,
size = 12)) +
theme(axis.title.y = element_text(angle = 360))
“`
|Item|Education Level Description|
|:——|:———–|
|0|No education|
|1|1st grade|
|2|2nd grade|
|3|3rd grade|
|4|4th grade|
|5|5th grade|
|6|6th grade|
|7|7th grade|
|8|8th grade|
|9|9th grade|
|10|10th grade|
|11|11th grade|
|12|12th grade|
|13|1 year of college|
|14|2 years of college|
|15|3 years of college|
|16|Bachelor degree|
|17|Bachelor +|
|99|Not state education level|
### Suicide 2003-2013 frequency by year & sex. Age_Value outlier are excluded.
“`{r, warning = FALSE, message = FALSE}
suicide.by.year.sex<- suicide.11.years %>%
filter(Age_Value<= 250) %>%
select(Resident_Status, Data_Year, Sex) %>%
group_by(Data_Year, Sex) %>%
count(Sex) %>%
rename(Count = n)
suicide.by.year.sex
“`
### Graphing suicide 2003-2013 frequency by sex.
“`{r, warning = FALSE, message = FALSE}
a1 <- ggplot(suicide.by.year.sex, aes(x = factor(Data_Year), y = Count, fill = Sex)) +
geom_bar(stat = “identity”, position = position_dodge(), width = 0.5) +
scale_x_discrete(breaks = seq(2003, 2013, 1)) +
scale_y_continuous(breaks = seq(0, 40000, by = 5000)) +
labs(x = ‘Year’,
y = ‘Frequency’,
title = ‘Suicide 2003-2013 by Year & Sex’,
fill = ‘Sex’) +
theme(plot.title = element_text(family = ‘Helvetica’,
color = ‘#666666’,
face = ‘bold’,
size = 18)) +
theme(axis.title = element_text(family = ‘Helvetica’,
color = ‘#666666’,
face = ‘bold’,
size = 12)) +
theme(axis.title.y = element_text(angle = 90))
a2 <- ggplot(suicide.by.year.sex, aes(x = Sex, y = Count, fill = Sex)) +
geom_bar(stat = “identity”, position = position_dodge(), width = 0.5) +
scale_y_continuous(breaks = seq(0, 40000, by = 10000)) +
labs(x = ‘Sex’,
y = ‘Frequency’) +
theme(plot.title = element_text(family = ‘Helvetica’,
color = ‘#666666’,
face = ‘bold’,
size = 18)) +
theme(axis.title = element_text(family = ‘Helvetica’,
color = ‘#666666’,
face = ‘bold’,
size = 12)) +
theme(axis.title.y = element_text(angle = 90)) +
facet_wrap(~ Data_Year)
grid.arrange(a1, a2, heights = 1:2)
“`
### Suicide statistic by age
“`{r, message = FALSE}
suicide.statistic<- suicide.11.years %>%
group_by(Sex) %>%
summarise(Group_Count = n(), Percentage = n() / length(.$Resident_Status),
Mean = mean(Age_Value),
Std = sd(Age_Value)) %>%
mutate(perc.pos = cumsum(Percentage) – Percentage / 2,
perc_text = paste0(round(Percentage * 100), “%”)) %>%
mutate(mean.pos = cumsum(Mean) – Mean / 2,
mean_text = round(Mean, 0))
suicide.statistic
“`
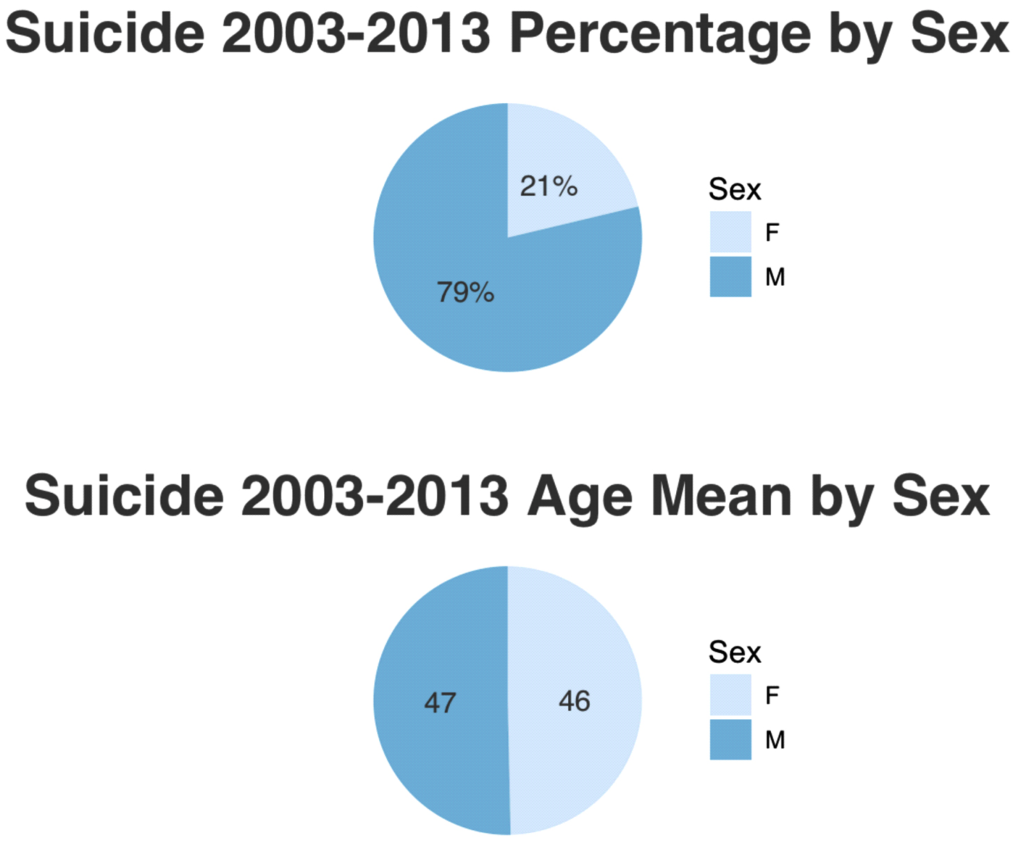
Please notice that the average age for both, male and female, are the same, 46 years old. Also notice that almost 79% of people that commit suicide are male and 21% are female.
### Graphing suicide 2003-2013 percentage & age mean by sex
“`{r , message = FALSE}
# Suicide 2003-2013 Percentage by Sex
p1 <- ggplot(suicide.statistic, aes(x = ‘’, y = Percentage, fill = Sex)) +
geom_bar(stat = “identity”, width = 1) +
geom_text(aes(y = perc.pos, label = perc_text),
size = 4,
colour = ‘#666666’,
family = ‘Helvetica’) +
coord_polar(theta = ‘y’, start = 0) +
labs(title = ‘Suicide 2003-2013 Percentage by Sex’) +
scale_fill_brewer(palette = ‘Blues’) +
theme_minimal() +
theme(axis.title.x = element_blank(),
axis.title.y = element_blank(),
axis.text.x = element_blank(),
panel.grid = element_blank(),
plot.title = element_text(family = ‘Helvetica’,
color = ‘#666666’,
face = ‘bold’,
size = 22))
# Suicide 2003-2013 Age Mean by Sex
p2 <- ggplot(suicide.statistic, aes(x = ‘’, y = Mean, fill = Sex)) +
geom_bar(stat = “identity”, width = 1) +
geom_text(aes(y = mean.pos, label = mean_text),
size = 4,
colour = ‘#666666’,
family = ‘Helvetica’) +
coord_polar(theta = ‘y’, start = 0) +
labs(title = ‘Suicide 2003-2013 Age Mean by Sex’) +
scale_fill_brewer(palette = ‘Blues’) +
theme_minimal() +
theme(axis.title.x = element_blank(),
axis.title.y = element_blank(),
axis.text.x = element_blank(),
panel.grid = element_blank(),
plot.title = element_text(family = ‘Helvetica’,
color = ‘#666666’,
face = ‘bold’,
size = 22))
grid.arrange(p1, p2)
“`
### Subset by age
“`{r, message = FALSE}
suicide.by.age<- suicide.11.years %>%
filter(Age_Value< 200) %>%
count(Age_Value)
suicide.by.age
“`
### Percentage group by Age_Value 39 to 57
“`{r , message = FALSE}
group.39.59 <- suicide.by.age %>%
filter(between(Age_Value, 39, 57))
sum(group.39.59$n) / count(suicide.11.years) * 100
“`
### Graphing suicide frequency by age
“`{r}
ggplot(suicide.by.age, aes(x = Age_Value, y = n, colour = n)) +
geom_bar(stat = “identity”, position = position_dodge()) +
scale_y_continuous(breaks = seq(0, 9000, by = 500)) +
labs(x = ‘Age’,
y = ‘Frequency’,
title = ‘Suicide 2003-2013 Frequency by Age’,
colour = ‘Frequency’) +
theme(plot.title = element_text(family = ‘Helvetica’,
color = ‘#666666’,
face = ‘bold’,
size = 18)) +
theme(axis.title = element_text(family = ‘Helvetica’,
color = ‘#666666’,
face = ‘bold’,
size = 12)) +
theme(axis.title.y = element_text(angle = 360))
“`
### Subset by ICD10:
There were many ICD10 with frequencies less than 10. I decide to create a subset that contains frequencies greater that 100.
“`{r, message = FALSE}
suicide.by.icd10 <- suicide.11.years %>%
count(ICD10) %>%
filter(n > 100) %>%
arrange(desc(n))
suicide.by.icd10
“`
|ICD10|Description|
|:—-|:———-|
|X74, X72|by discharge of firearms|
|X73|Self-harm by rifle, shotgun and larger firearm discharge|
|X70|by hanging, strangulation and suffocation|
|X60, X64|by and exposure to drugs and other biological substances|
|X61|by and exposure to drugs and other biological substances|
|X62|by and exposure to drugs and other biological substances|
|X63|by and exposure to drugs and other biological substances|
|X65, X66, X68, X69|by and exposure to other and unspecified solid or liquid substances and their vapors|
|X67|by and exposure to other gases and vapors|
|X66|by and exposure to other and unspecified solid or liquid substances and their vapors|
|X44|by and exposure to drugs and other biological substances|
|X80|by jumping from a high place|
Table is create for ICD10 with high frequency. Description for X73 was not found anywhere in the documentation files. The internet was searched for a accurate description and many websites agree that X73 description is a “Self-harm by rifle, shotgun and larger firearm discharge”. The website can be accessed [here.](http://icdlist.com/icd-10/X73.9)
### Graphing frequency of ICD10
“`{r, message = FALSE}
ggplot(suicide.by.icd10, aes(x = ICD10, y = n, fill = n)) +
geom_bar(stat = “identity”, position = position_dodge()) +
scale_y_continuous(breaks = seq(0, 150000, by = 15000)) +
labs(x = ‘ICD10’,
y = ‘Frequency’,
title = ‘Suicide 2003-2013 ICD10 Frequency’,
fill = ‘Frequency’) +
theme(plot.title = element_text(family = ‘Helvetica’,
color = ‘#666666’,
face = ‘bold’,
size = 18)) +
theme(axis.title = element_text(family = ‘Helvetica’,
color = ‘#666666’,
face = ‘bold’,
size = 12)) +
theme(axis.title.y = element_text(angle = 360),
axis.text.x = element_text(angle = 45, hjust = 1))
“`
### Calculating percentage of people that commit suicide by discharge of firearms.
“`{r}
suicide.by.icd10 %>%
filter(trimws(ICD10) %in% c(‘X74’, ‘X73’, ‘X72’)) %>%
summarise(Sum = sum(n) / nrow(suicide.11.years) * 100)
“`
Please notice that **203,146** people committed suicide by discharge of firearms.
“`{r}
percentage.by.icd10 <- suicide.by.icd10 %>%
mutate(Percentage = n / nrow(suicide.11.years) * 100)
“`
“`{r, message = FALSE}
ggplot(percentage.by.icd10, aes(x = ICD10, y = Percentage, fill = Percentage)) +
geom_bar(stat = “identity”, position = position_dodge()) +
scale_y_continuous(breaks = seq(0, 100, by = 10)) +
labs(x = ‘ICD10’,
y = ‘Percentage %’,
title = ‘Suicide 2003-2013 ICD10 Percentage’,
fill = ‘Percentage’) +
theme(plot.title = element_text(family = ‘Helvetica’,
color = ‘#666666’,
face = ‘bold’,
size = 18)) +
theme(axis.title = element_text(family = ‘Helvetica’,
color = ‘#666666’,
face = ‘bold’,
size = 12)) +
theme(axis.title.y = element_text(angle = 360),
axis.text.x = element_text(angle = 45, hjust = 1))
“`
Please notice that almost **51%** people committed suicide by discharge of firearms. That is the combination of X72, X73, and X74.
### Subset by high school diploma & committed suicide by discharge of firearms.
“`{r , message = FALSE}
# Counting all with high school diploma
hsd<- suicide.11.years %>%
filter(Education == 12) %>%
count(Education)
hsd
# Counting all with high school diploma & committed suicide by discharge of firearms.
suicide.hs.fa<- suicide.11.years %>%
filter(Education == 12, trimws(ICD10) %in% c(‘X74’, ‘X73’, ‘X72’)) %>%
count(Education)
suicide.hs.fa
# Calculating percentage of people with high school diploma & committed suicide by discharge of firearms.
suicide.hs.fa$n / hsd$n * 100
“`
Please notice that the percentage of people with an education level of high school diploma & committed suicide by discharge of firearms is **55%**, which is higher than all the people that committed suicide by discharge of firearms from 2003-2013, which is **51%**. |